Load Data - Harvest
Overview
To load PDS4 data into Registry you have to use Harvest software to extract metadata from PDS4 products (labels) and load extracted metadata into OpenSearch database.
This document describes how to load data with Harvest command-line tool.
Prerequisites
Your connection to the registry service is setup, see Connection Setup.
Harvest command-line tool is installed.
Harvest Quick Start
To run Harvest you need a job configuration file (XML). The configuration file has several sections such as Registry (OpenSearch) configuration and the path to the data.
Example configuration files are located in <INSTALL_DIR>/conf/examples.
The most useful configuration for an Harvest’s job is conf/examples/directories.xml.
Registry (OpenSearch) acess configuration:
<registry auth="/path/to/auth.cfg">file:///path/to/config/mcp_dev.xm</registry>
Use the paths of the files identified in Connection Setup.
The path to the data:
<load>
<directories>
<path>/data/geo/urn-nasa-pds-kaguya_grs_spectra</path>
</directories>
</load>
And the URL prefix for the data:
<fileInfo>
<!-- UPDATE with your own local path and base url where pds4 archive is published -->
<fileRef replacePrefix="/data/geo/" with="https://pds-geosciences.wustl.edu/lunar/" />
</fileInfo>
If you save this file as /tmp/kaguya.xml and run Harvest
harvest -c /tmp/kaguya.xml
All XML files in /data/geo/urn-nasa-pds-kaguya_grs_spectra folder and its subfolders will be processed. All metadata from PDS4 labels will be extracted and loaded into Registry (OpenSearch).
You will see multiple log messages similar to these:
...
[INFO] Processing C:\Geo\kaguya_grs_spectra\data_ephemerides\kgrs_ephemerides.xml
[INFO] Processing C:\Geo\kaguya_grs_spectra\data_spectra\kgrs_calibrated_spectra_per1.xml
[INFO] Processing C:\Geo\kaguya_grs_spectra\data_spectra\kgrs_calibrated_spectra_per2.xml
[INFO] Processing C:\Geo\kaguya_grs_spectra\data_spectra\kgrs_calibrated_spectra_per3.xml
[INFO] Processing C:\Geo\kaguya_grs_spectra\data_spectra\spectra_data_collection_inventory.xml
...
[SUMMARY] Summary:
[SUMMARY] Skipped files: 0
[SUMMARY] Processed files: 14
[SUMMARY] File counts by type:
[SUMMARY] Product_Bundle: 1
[SUMMARY] Product_Collection: 4
[SUMMARY] Product_Context: 3
[SUMMARY] Product_Document: 2
[SUMMARY] Product_Observational: 4
[SUMMARY] Package ID: e46f6ba9-6151-48ee-b822-b0536e3e4bd9
To quickly check that data was loaded you can query Registry indices using Registry Client
Note
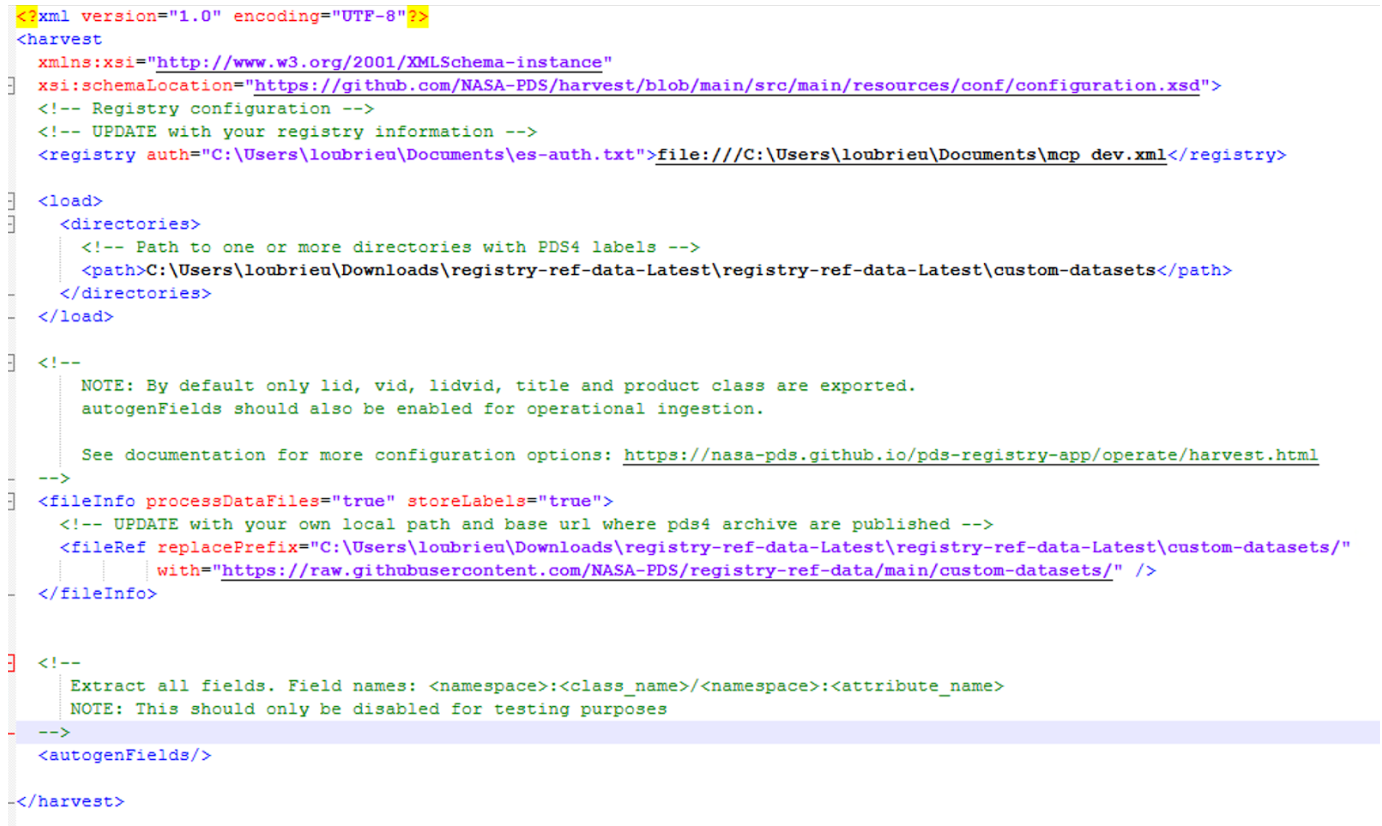
On Windows, the harvest job configuration file would look as follows:
Next Steps
You can see additional harvest options by running:
./bin/harvest -help
The harvest job configuration file provides also additional options described in Detailed Harvest Configuration.
You can validate the products uploaded in the registry using registry-client.
Warning
Due to refresh rates and indexation delays, it may take up to a few hours before the data becomes visible.
When ready for public release, you need to update the archive status